Note
Click here to download the full example code or to run this example in your browser via Binder
Classification Using Hidden Markov Model
This is a demonstration using the implemented forward algorithm in the context of a hidden Markov model to classify multiple targets.
We will attempt to classify 3 targets in an undefined region.
All Stone Soup imports will be given in order of usage.
from datetime import datetime, timedelta
import numpy as np
from stonesoup.models.transition.categorical import MarkovianTransitionModel
from stonesoup.types.groundtruth import CategoricalGroundTruthState
from stonesoup.types.groundtruth import GroundTruthPath
Ground Truth
The targets may take one of two discrete hidden classes: ‘bike’, and ‘car’.
A target may be able to transition from one class to another (this could be considered as a
person switching from riding a bike to driving a car and vice versa).
This behaviour will be modelled in the transition matrix of the
MarkovianTransitionModel. This transition matrix is a Markov process matrix, whereby
it is assumed that the state of a target is wholly dependent on its previous state, and nothing
else.
A CategoricalState class is used to store information on the classification/category
of the targets. The state vector will define a categorical distribution over the 2 possible
classes, whereby each component defines the probability that a target is of the corresponding
class. For example, the state vector (0.2, 0.8), with category names (‘bike’, ‘car’)
indicates that a target has a 20% probability of being class ‘bike’ and an 80% probability of
being class ‘car’ etc.
It does not make sense to have a true target being a distribution over the possible classes, and
therefore the true categorical states will have binary state vectors indicating a specific class
(i.e. a ‘1’ at one state vector index, and ‘0’s elsewhere). This can be considered as stating
there is a 100% probability that the target is of a particular class. We specify that there
should be noise when functioning our transition model in order to sample the resultant
distribution and receive this binary vector.
The CategoricalGroundTruthState class inherits directly from the base
CategoricalState class.
The category and timings for one of the ground truth paths will be printed.
transition_matrix = np.array([[0.8, 0.2], # P(bike | bike), P(bike | car)
[0.4, 0.6]]) # P(car | bike), P(car | car)
category_transition = MarkovianTransitionModel(transition_matrix=transition_matrix)
start = datetime.now()
hidden_classes = ['bike', 'car']
# Generating ground truth
ground_truths = list()
for i in range(1, 4): # 4 targets
state_vector = np.zeros(2) # create a vector with 2 zeroes
state_vector[np.random.choice(2, 1, p=[1 / 2, 1 / 2])] = 1 # pick a random class out of the 2
ground_truth_state = CategoricalGroundTruthState(state_vector,
timestamp=start,
categories=hidden_classes)
ground_truth = GroundTruthPath([ground_truth_state], id=f"GT{i}")
for _ in range(10):
new_vector = category_transition.function(ground_truth[-1],
noise=True,
time_interval=timedelta(seconds=1))
new_state = CategoricalGroundTruthState(
new_vector,
timestamp=ground_truth[-1].timestamp + timedelta(seconds=1),
categories=hidden_classes
)
ground_truth.append(new_state)
ground_truths.append(ground_truth)
for states in np.vstack(ground_truths).T:
print(f"{states[0].timestamp:%H:%M:%S}", end="")
for state in states:
print(f" -- {state.category}", end="")
print()
15:56:21 -- bike -- bike -- bike
15:56:22 -- bike -- car -- bike
15:56:23 -- bike -- car -- bike
15:56:24 -- car -- bike -- bike
15:56:25 -- car -- car -- car
15:56:26 -- bike -- car -- car
15:56:27 -- car -- car -- car
15:56:28 -- car -- car -- bike
15:56:29 -- car -- car -- car
15:56:30 -- car -- car -- car
15:56:31 -- bike -- bike -- bike
Measurement
Using a Hidden Markov model, it is assumed the true class of a target cannot be directly
observed (hence ‘hidden’), and instead observations that are dependent on this class are taken.
In this instance, observations of the targets’ sizes are taken (‘small’, ‘medium’ or ‘large’).
The relationship between true class and observed size is modelled by the emission matrix of the
MarkovianMeasurementModel, which is used by the HMMSensor to
provide CategoricalDetection types.
We will model this such that a ‘bike’ has a very small chance of being observed as a ‘big’
target etc.
from stonesoup.models.measurement.categorical import MarkovianMeasurementModel
from stonesoup.sensor.categorical import HMMSensor
E = np.array([[0.8, 0.1], # P(small | bike), P(small | car)
[0.19, 0.3], # P(medium | bike), P(medium | car)
[0.01, 0.6]]) # P(large | bike), P(large | car)
model = MarkovianMeasurementModel(emission_matrix=E,
measurement_categories=['small', 'medium', 'large'])
eo = HMMSensor(measurement_model=model)
# Generating measurements
measurements = list()
for index, states in enumerate(np.vstack(ground_truths).T):
if index == 5:
measurements_at_time = set() # Give tracker chance to use prediction instead
else:
measurements_at_time = eo.measure(states)
timestamp = next(iter(states)).timestamp
measurements.append((timestamp, measurements_at_time))
print(f"{timestamp:%H:%M:%S} -- {[meas.category for meas in measurements_at_time]}")
15:56:21 -- ['small', 'small', 'small']
15:56:22 -- ['large', 'small', 'medium']
15:56:23 -- ['small', 'small', 'large']
15:56:24 -- ['medium', 'small', 'small']
15:56:25 -- ['large', 'medium', 'large']
15:56:26 -- []
15:56:27 -- ['large', 'large', 'medium']
15:56:28 -- ['large', 'small', 'large']
15:56:29 -- ['large', 'large', 'medium']
15:56:30 -- ['small', 'large', 'large']
15:56:31 -- ['small', 'small', 'medium']
Tracking Components
Predictor
A HMMPredictor specifically uses MarkovianTransitionModel types to
predict.
from stonesoup.predictor.categorical import HMMPredictor
# It would be cheating to use the same transition model as in ground truth generation!
transition_matrix = np.array([[0.81, 0.19], # P(bike | bike), P(bike | car)
[0.39, 0.61]]) # P(car | bike), P(car | car)
category_transition = MarkovianTransitionModel(transition_matrix=transition_matrix)
predictor = HMMPredictor(category_transition)
Updater
from stonesoup.updater.categorical import HMMUpdater
updater = HMMUpdater()
Hypothesiser
A HMMHypothesiser is used for calculating categorical hypotheses.
It utilises the ObservationAccuracy measure: a multi-dimensional extension of an
‘accuracy’ score, essentially providing a measure of the similarity between two categorical
distributions.
from stonesoup.hypothesiser.categorical import HMMHypothesiser
hypothesiser = HMMHypothesiser(predictor=predictor, updater=updater)
Data Associator
We will use a standard GNNWith2DAssignment data associator.
from stonesoup.dataassociator.neighbour import GNNWith2DAssignment
data_associator = GNNWith2DAssignment(hypothesiser)
Prior
As we are tracking in a categorical state space, we should initiate with a categorical state for the prior. Equal probability is given to all 3 of the possible hidden classes that a target might take (the category names are also provided here).
from stonesoup.types.state import CategoricalState
prior = CategoricalState([1 / 2, 1 / 2], categories=hidden_classes)
Initiator
For each unassociated detection, a new track will be initiated. In this instance we use a
SimpleCategoricalMeasurementInitiator, which specifically handles categorical state
priors.
from stonesoup.initiator.categorical import SimpleCategoricalMeasurementInitiator
initiator = SimpleCategoricalMeasurementInitiator(prior_state=prior, updater=updater)
Deleter
We can use a standard UpdateTimeStepsDeleter.
from stonesoup.deleter.time import UpdateTimeStepsDeleter
deleter = UpdateTimeStepsDeleter(2)
Tracker
We can use a standard MultiTargetTracker.
from stonesoup.tracker.simple import MultiTargetTracker
tracker = MultiTargetTracker(initiator, deleter, measurements, data_associator, updater)
Tracking
tracks = set()
for time, ctracks in tracker:
tracks.update(ctracks)
print(f"Number of tracks: {len(tracks)}")
for track in tracks:
certainty = track.state_vector[np.argmax(track.state_vector)][0] * 100
print(f"id: {track.id} -- category: {track.category} -- certainty: {certainty}%")
for state in track:
_time = state.timestamp.strftime('%H:%M')
_type = str(type(state)).replace("class 'stonesoup.types.", "").strip("<>'. ")
state_string = f"{_time} -- {_type} -- {state.category}"
try:
meas_string = f"associated measurement: {state.hypothesis.measurement.category}"
except AttributeError:
pass
else:
state_string += f" -- {meas_string}"
print(state_string)
print()
Number of tracks: 3
id: 3f047d2b-076b-4408-851f-c9211bb0152c -- category: bike -- certainty: 92.80897382982855%
15:56 -- update.CategoricalStateUpdate -- bike -- associated measurement: small
15:56 -- update.CategoricalStateUpdate -- bike -- associated measurement: small
15:56 -- update.CategoricalStateUpdate -- bike -- associated measurement: small
15:56 -- update.CategoricalStateUpdate -- bike -- associated measurement: small
15:56 -- update.CategoricalStateUpdate -- bike -- associated measurement: medium
15:56 -- prediction.CategoricalStatePrediction -- car
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: medium
15:56 -- update.CategoricalStateUpdate -- bike -- associated measurement: small
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: medium
15:56 -- update.CategoricalStateUpdate -- bike -- associated measurement: small
15:56 -- update.CategoricalStateUpdate -- bike -- associated measurement: small
id: e1693508-4ae4-4512-a348-e0d201435d4a -- category: bike -- certainty: 71.61815692511814%
15:56 -- update.CategoricalStateUpdate -- bike -- associated measurement: small
15:56 -- update.CategoricalStateUpdate -- bike -- associated measurement: medium
15:56 -- update.CategoricalStateUpdate -- bike -- associated measurement: small
15:56 -- update.CategoricalStateUpdate -- bike -- associated measurement: small
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: large
15:56 -- prediction.CategoricalStatePrediction -- car
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: large
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: large
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: large
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: large
15:56 -- update.CategoricalStateUpdate -- bike -- associated measurement: small
id: 80bcdff3-482d-4629-b446-e511ff3f27d1 -- category: car -- certainty: 83.34948005370167%
15:56 -- update.CategoricalStateUpdate -- bike -- associated measurement: small
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: large
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: large
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: medium
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: large
15:56 -- prediction.CategoricalStatePrediction -- car
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: large
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: large
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: large
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: large
15:56 -- update.CategoricalStateUpdate -- car -- associated measurement: medium
Metric
Determining tracking accuracy. In calculating how many targets were classified correctly, only tracks with the highest classification certainty are considered. In the situation where probabilities are equal, a random classification is chosen.
excess_tracks = len(tracks) - len(ground_truths) # target value = 0
sorted_tracks = sorted(tracks,
key=lambda track: track.state_vector[np.argmax(track.state_vector)][0],
reverse=True)
best_tracks = sorted_tracks[:3]
true_classifications = [ground_truth.category for ground_truth in ground_truths]
track_classifications = [track.category for track in best_tracks]
num_correct_classifications = 0 # target value = num ground truths
for true_classification in true_classifications:
for i in range(len(track_classifications)):
if track_classifications[i] == true_classification:
num_correct_classifications += 1
del track_classifications[i]
break
print(f"Excess tracks: {excess_tracks}")
print(f"No. correct classifications: {num_correct_classifications}")
Excess tracks: 0
No. correct classifications: 2
Plotting
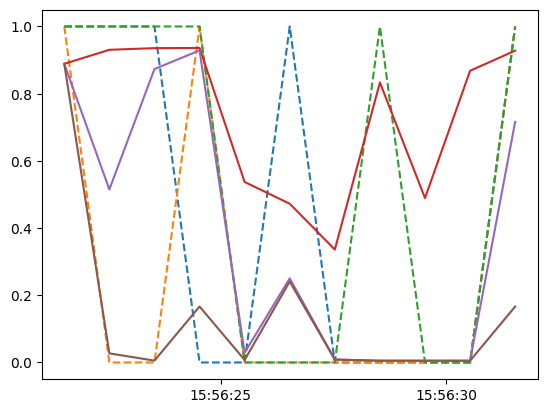
Plotting the probability that each one of our targets and tracks is a ‘bike’ will help to visualise this 2-hidden class problem.
Dotted lines indicate ground truth probabilities, and solid lines for tracks.
import matplotlib.pyplot as plt
def plot(path, style):
times = list()
probs = list()
for state in path:
times.append(state.timestamp)
probs.append(state.state_vector[0])
plt.plot(times, probs, linestyle=style)
for truth in ground_truths:
plot(truth, '--')
for track in tracks:
plot(track, '-')
Total running time of the script: ( 0 minutes 0.224 seconds)