Framework Design [1]
Stone Soup is initially targeted at two different groups of users:
Academics conducting research into tracking and state estimation, looking to quickly develop algorithms, and compare against other algorithms assessed against metrics.
User, owners and processors of real data, looking to identify the best approach for their application, without the need for deep expertise required to implement many algorithms.
The central theme of the Stone Soup design philosophy is interchangeability. The framework is designed with the idea that users can easily insert their own components into existing constructs, and that they could mix and match components in new and unexpected ways. In support of this goal, the Stone Soup code architecture has been built on the principles of modularity and uniformity of external interfaces.
Stone Soup is object oriented and makes use of encapsulation, abstraction and inheritance:
- Abstraction
Stone Soup trackers are built as hierarchical objects. For example, a
MultiTargetTrackerobject may contain trackInitiator, a trackDeleter,Detector,DataAssociator, andUpdaterobjects. Each of these objects is defined by an abstract class that specifies the external interface for that class; that is, the parameters and functions an object of that class must make available to the outside world.- Inheritance
An example, the
Updaterabstract class specifies that anUpdaterobject must have ameasurement_modelattribute, and that it must have methodspredict_measurement()andupdate()that returns aMeasurementPredictionandStateobject respectively. Therefore, all implementations of Updaters in Stone Soup (KalmanUpdater,ExtendedKalmanUpdater,ParticleUpdater, etc.) must have the specified elements.- Encapsulation
With the
Updaterexample, this approach ensures that different Updaters are interchangeable (within limits), and that theTrackercan utilize them without knowing the details of theUpdaterimplementation.
Components
Stone Soup has a number of components used to both build a algorithm, but also enable an environment for testing and assessment.
Enabling Components
The enabling components in Stone Soup consist of components for reading/simulating data, feeding into the algorithm, and then writing and assessing the output.
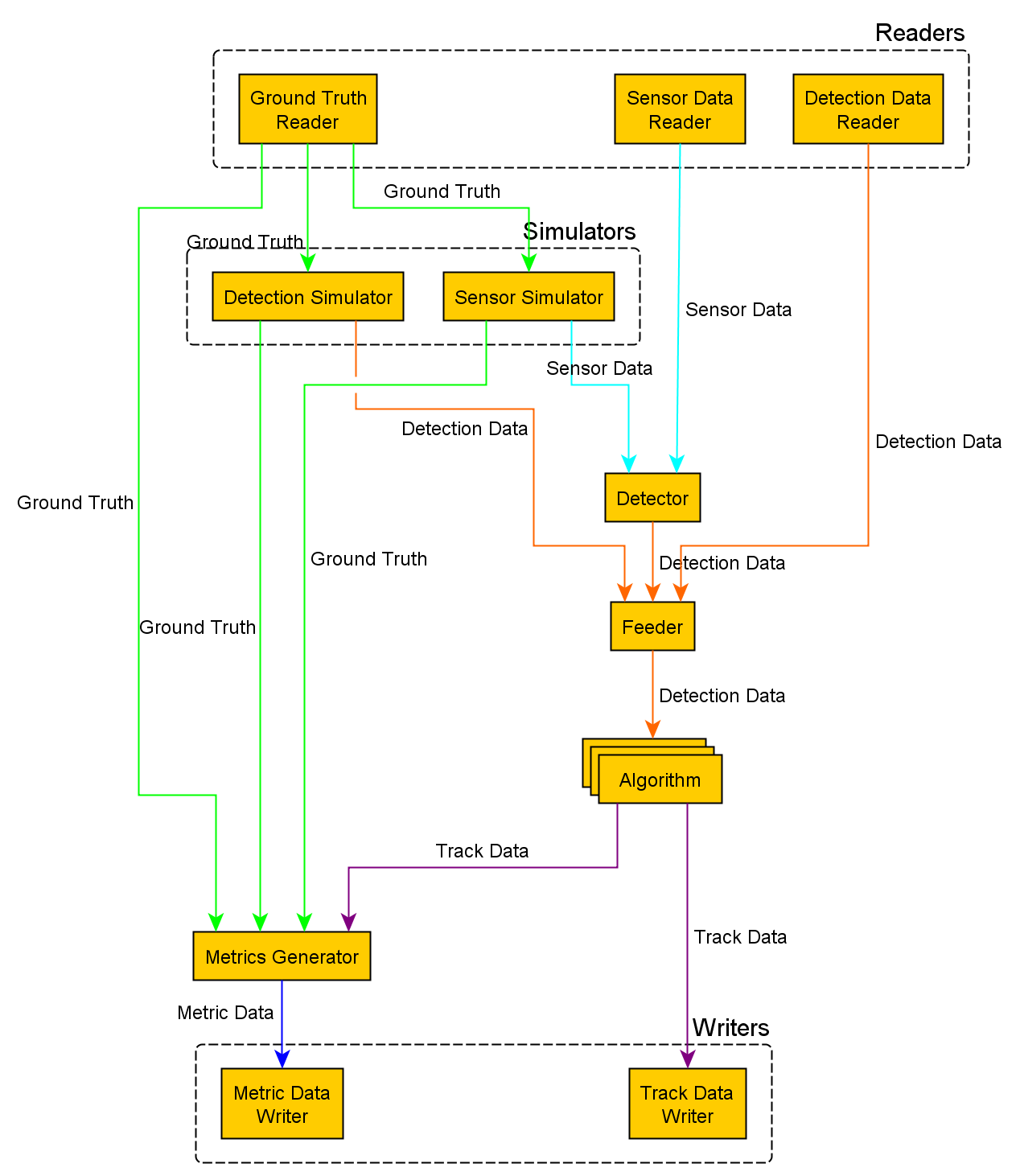
Stone Soup Logical Data Flow
The figure above shows the overall flow of data from the various components, showing for example
how Detection data can be read directly from a DetectionReader, or maybe via
a DetectionSimulator which uses GroundTruthPath data. This could also include
reading data direct from a sensor. Outputs can also be passed into MetricGenerator, or
written to file or database for later analysis. Note that all these components are optional.
Algorithm Components
The algorithm components are those used to create a tracking or state estimation algorithm, where
the main component (e.g. MultiTargetTracker) will define the parts required. These are
currently mainly focused on target tracking use case in Stone Soup, but intent is also for general
state estimation as well.
Stone Soup Multi Target Tracker
The figure above shows an example of a MultiTargetTracker, but note that other types of
algorithms may use different components, and different combination/sequence. In this examples, this
is processing detections over time, which then is predicting, associating, updating, initiating and
deleting tracks. By using in here a KalmanPredictor, a KalmanUpdater, and a
GaussianInitiator, this becomes a Kalman tracker; but with a
ParticlePredictor, a ParticleUpdater, and a ParticleInitiator,
this becomes a Particle tracker.
Data Types
A key part of Stone Soup is the data types, that allow data to be passed between components. A
fundamental example of this in Stone Soup is the State data type. This has a
state_vector, and optional timestamp, which describes the state of
something at a particular time. One child class of this is the Detection class, which
describes a measurement from a sensor at a particular time; or the GaussianState which
not only has a state_vector (Gaussian mean), but also has a
covar (Gaussian covariance) and such describes the state with uncertainty
in the form of a multivariate Gaussian distribution.
Stone Soup also employs duck typing, a technique that means that data types are flexible. For
example, a State (as mentioned above) and GroundTruthPath (describing how
target’s true state changes over time), both have a similar interface in terms of have a state
vector and timestamp (in case of GroundTruthPath the most recent
GroundTruthState). They therefore can both be used with TransitionModel
instances, allowing models to be used for both target prediction (in case with
Predictor) and in simulating targets (in case with Platform).
Footnotes